[DevLog] AWS 교육 (Analytics Immersion Day) 참가
개요
2023년 8월 25일 AWS Analytics Immersion Day 에 참석하였다.
Intro
AWS Analytics IMD - Intro
Q&A About Analytics
- Why Analytics?
- Q1. 왜 DB만으로는 안 되고 Analytics 를 사용해야 하는지? 예를 들어 PS 고객 중에는 사용자 activity log 를 아직도 rdb에 구축하는 경우가 있음. 근본적으로 data warehouse 를 구축하면 더 할 수 있는 것이 무엇인지?
- A1. Database 는 single node system 이고, Analytics 는 muliple nodes 로 병렬 처리가 가능하다. 그리고 database 는 row storage 형식을 취하지만, analytics database 는 column-storage format 이기 때문에, DB 엔진이 처음부터 끝까지 읽어서 처리할 필요가 없다. 그리고, Analytics 라고 하면 복잡한 시스템을 구축해야 할 것 같지만 AWS 에서는 서버-리스 서비스를 지원해서 소규모로 시작할 수 있는 것이 강점이다.
- How to Start?
- Q2. 뭐 부터 시작해야 하는지? 그리고 어떤 데이터를 어떻게 수집해야 하는지?
- A2. 모든 데이터를 다 웨어하우스에 옮기는 것 대신, 가장 비즈니스의 kpi 를 예측 (measure) 하기 위해 사용하고 싶은 데이터를 정리하고 working backwards 하는 것을 추천한다. 그리고 data-driven-everything 이라고 부르는 B2E 프로그램을 사용해봐도 좋다.
- Global CSP compet
- Q3. Azure, Google 등과 비교해서 AWS Datalake 의 차이는?
- A3. 해당 서비스를 가장 오래 운영함 (얼마 전에 10주년을 맞았다) 아마존에서는 딥 러닝을 하기 위해 전혀 코드를 작성하지 않아도 데이터를 옮길 수 있다. Google 은 최근 가격을 인상. Azure 이 현재 제시하는 올-인-원 솔루션은 새로운 컨셉이 아님. AWS는 다양한 도메인에 대한 분석이 가능하도록, 예를 들어 Healthcare 분야라면 Health-Lake 를 제공.
- AI/ML
- Q4. Analytics 로 AI/ML 과 시너지를 내는 방법.
- A4. Data 가 좋지 않다면, 아무리 모델을 optimize 하려고 해도 잘 되지 않을 것이다. Right Data 에 Rigth time 에 접근할 수 있도록 하는 것이 중요. 데이터 퀄리티를 높이기 위해 체크하는 작업과, 통합 작업 등을 편하게 하기 위해서는 데이터에 대한 정확한 이해가 필요하다. AWS Glue 라는 서비스는 데이터의 적재 이전에 그것이 정말 필요한 정보를 담고 있는지 확인하고, 피드백을 줄 수 있도록 한다.
- Local traditional analytic solution
- Q5. 전통적인 방법과 Cloud 에 구축하는 방법은 무엇이 다른가?
- A5. 데이터 복제 등을 고려했을 때, Cloud 에 올리는 것이 Cost-effective 함. 또한 Share 가 편리하다.
AWS Analytics 소개
- Data Lake : 간단히 말하면, ‘S3에 데이터를 그냥 넣어놓자. 그리고 카탈로그를 잘 하면 되지 않을까?’ 하는 개념 -> S3 + Glue 로 Database 처럼 사용할 수 있으며, 서버리스 쿼리 서비스인 Athena 를 함께 사용한다.
- AWS Glue Data Catalog Crawlers : 자동으로 데이터 카탈로그를 구축, 동기화 상태를 유지
- Real Time Analysis : Amazon Redshift 와 Amazon Aurora 제로 ETL 통합, S3에서 RedShift 로 자동화된 파일 수집 (현재 개발 진행 중인 서비스)
Lab#1 : AWS Glue, Amazon Athena
환경구성 확인 및 실습
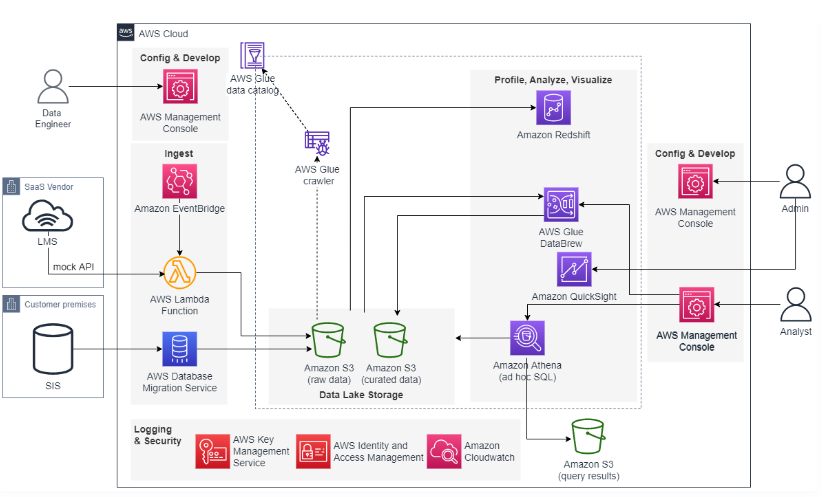
요약
- 데이터 인입부터 시각화까지 전 과정을 실습
- 데모에 사용할 것은 Student Imformation 등 LMS 사용, S3에 저장되어 있는 raw data, curated data, query results 세 개의 버킷이 생성되어 있음.
- 진행 예정 세션
- API Call 해서 Database 에 데이터 적재하는 부분은 Skip
- Data Lake Storage 에 접근, Glue Crawler 로 생성된 카탈로그 확인
- Athena 로 data 확인
- QuickSight 로 시각화
- Amazon RedShift 를 생성하고 사용
개인적으로 해보고 싶다면 GUID 를 생성해서 self-paced lab을 진행 가능.
Glue
한 줄 요약 : 전처리 (ETL)
- 기존 ETL 과 비교
- 전통적인 ETL 은 확장성이 제한되어 있고, 라이선스 비용이 높고, 특정 솔루션에 종속됨
- DIY Big Data platform 은 관리가 어렵고, 전문성이 필요
- 반면 Glue 는 서버리스 솔루션이고, 종속성이 없음
- AWS Glue data integration engines
- 서버리스, 빠름, 비용 절감
- Auto Scaling : 비용 절감을 위해 Worker 개수 자동 조정
- Streaming : 작은 worker 유형 (예를 들어, 1 DPU 가 4 CPU 에 Core 16개 기준일 때, 0.25x 개 단위로 판매)
- Flex : 예비 용량으로 실행
- Scale, Reliability
- Autoscaling 이 잘 된다고 함
- Apache Spark, python
- 개발자에게 친숙한 언어 사용
- 데이터 처리 시 분산 환경 Pandas API 사용
- Build scalable applicatin with Ray
- 단일 python node 사용 시와 달리, Ray Task 를 사용하여 큰 데이터에 적용 가능 (서울 지역은 현재 지원 X)
- Connectors
- 빌트인 커넥터를 쓰거나, Open-source 기반 커넥터를 개발 가능
- Authoring Solutions
- Visual ETL, Notebooks (Python command line 작성 가능), Code Editor 등
- Transformation 시 개발한 소스를 팀 간 공유 가능
- Operationalize
- 다양한 Workflow 오케스트레이션 tools 이 있음
- 예를 들어, S3에 Data Event 가 있을 시 Amazon EventBridge 로 Trigger가 되어, Glue Workflow 를 시작할 수 있음
- Data Management
- 수용성이 좋고, 크롤러를 사용하면 카탈로그를 볼 수 있고, 민감한 데이터를 식별 및 마스킹 가능
Athena
한 줄 요약 : 쿼리 엔진
- SQL 또는 Python 을 사용해서 데이터를 쿼리
실습
준비된 raw data 를 S3에 Load 하는 것부터 시작
- Key Management Service (KMS)에 Key users 추가
- Lambda 로 S3 에 raw data 추가
- Glue Crawler 실행 (AWS Cloudshell 에서 실행해도 되고, Crawlers 콘솔에서 실행해도 됨)
- Athena 쿼리 날리고, 테이블 생성 확인
- Athena Query Editor 에서 바로 쿼리 할 수 있음
Lab#2 : AWS Glue DataBrew
요약
‘노코드’로 시각적 인터페이스를 제공하여, ETL 작업을 정의하고 쉽게 할 수 있도록 돕는 서비스
AWS Glue DataBrew
- Usage Flow
- 데이터 세트 정의
- 프로젝트를 만들고 레시피 (데이터 변환 단계) 정의
- 레시피 생성
- JOB 작성 & 실행
- AWS EventBridge & Step Function 과 스케쥴 실행 연동 가능
- 특정 타이밍에 EventBridge 에 이벤트를 발행해, event-driven 처리를 구현 가능
- AWS 계정당 동시 JOB, 데이터 세트 등에 기본 할당량 값이 있으나 soft limit 이기 때문에 조절 가능
- 과금은 사용 세션과 DataBrewJOB 을 합산하여 계산
실습
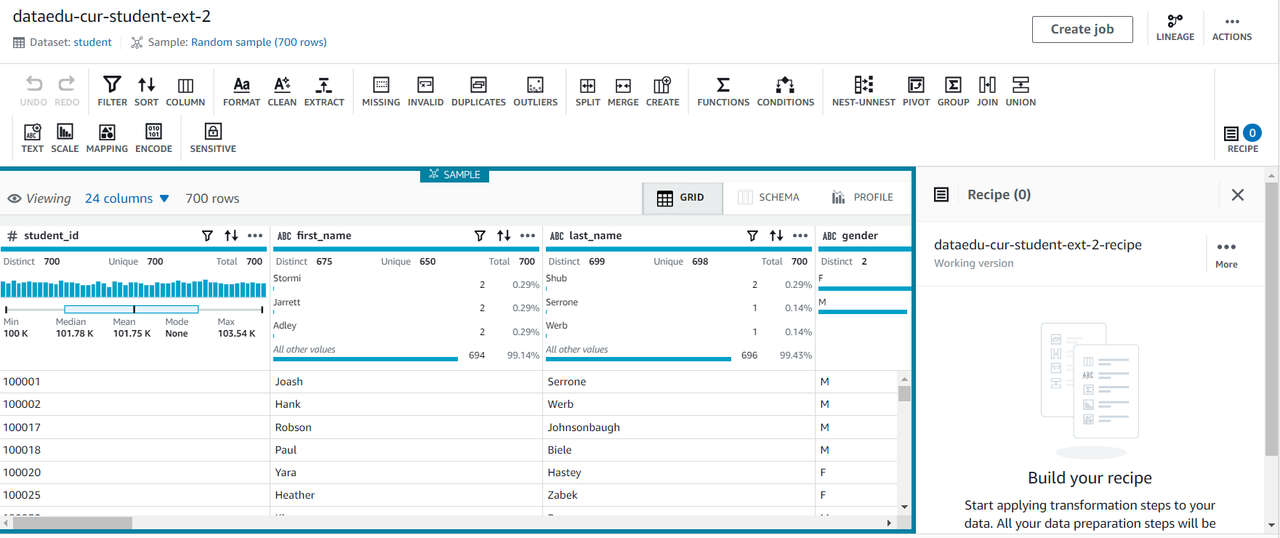
- Profile raw SIS datasets
- 데이터 셋을 생성
- Profile Job 생성
- Profile Job 실행
- Combine raw SIS datasets
- 데이터 셋을 생성
- 레시피를 생성 (실습 시에는 Join, Rename 두 가지를 사용)
- 레시피를 Publish
- Recipe Job 을 생성하고, 실행
이렇게 데이터를 추출하고 전처리하는 동작을 설계할 수 있음. (S3 storage 에 저장하는 방법으로는 parquet, snappy 압축을 사용하기를 권장하고 있음)
- Curating the student data lake using SQL
- LMS 데이터 셋을 생성
- Athena 쿼리 창에서 쿼리 날리기
- S3 에 데이터가 저장된 것을 확인
- 쿼리문 예시
CREATE TABLE "db_cur_lmsdemo"."agg_pageview_count_by_user_course" WITH ( external_location = 's3://dataedu-curated-_guid_/lmsdemo/agg_pageview_count_by_user_course/', format = 'PARQUET', parquet_compression = 'SNAPPY' ) AS SELECT user_id, course_id, timestamp_year, timestamp_month, timestamp_day, timestamp_hour, count(id) AS pageview_count FROM "db_raw_lmsdemo"."requests" GROUP BY user_id, course_id, timestamp_year, timestamp_month, timestamp_day, timestamp_hour
Lab#3 : QuickSight
요약
클라우드 네이티브 서버리스 BI 서비스로, 사용량 기반 요금제 및 ML 인사이트로 고급 분석 수행 (쉽게 생각해서, 엑셀 피봇 차트 작성과 유사)
Amazon Quicksight
- 사용 사례 : 대시보드 제공, Insight 내장, 기업 보고서 작성
- 커스텀 모델 생성 후 임베디드 가능
- Data Connectivity
- 엑셀, CSV, 다양한 클라우드 및 어플리케이션과 통합 가능
- SPICe 엔진 사용, 사용자 수와 관계 없이 성능과 규모를 제공
- AWS 데이터 소스와 함께 사용하면 거버넌스에서 활용성이 향상됨
- AWS Glue Crawler 사용 시, Glue data 카탈로그를 생성 후 보안 및 권한 설정 적용 후 데이터 쿼리, 시각화
- AWS GLUE Databrew 사용 시, 코드 없이 데이터를 정제한 뒤 준비된 데이터를 S3 로 내보내고, SPICE 로 데이터를 가져온 후 시각화
- Augmented Analytics
- Q : ML 기반 NLQ로 셀프 서비스 분석 (질문에 자동으로 답변하는 table 생성)
- Enterprise Reporting
- PDF 생성 시 페이지 넘어갈 때 표가 잘리지 않고 테이블이 예쁘게 나온다고 함
- 그 외 예약 전송, 스냅샷 기록 등 제공
실습
- Quicksight
- 가입
- KMS 키 등록
- 데이터 셋 생성
- 그래프 생성 및 편집
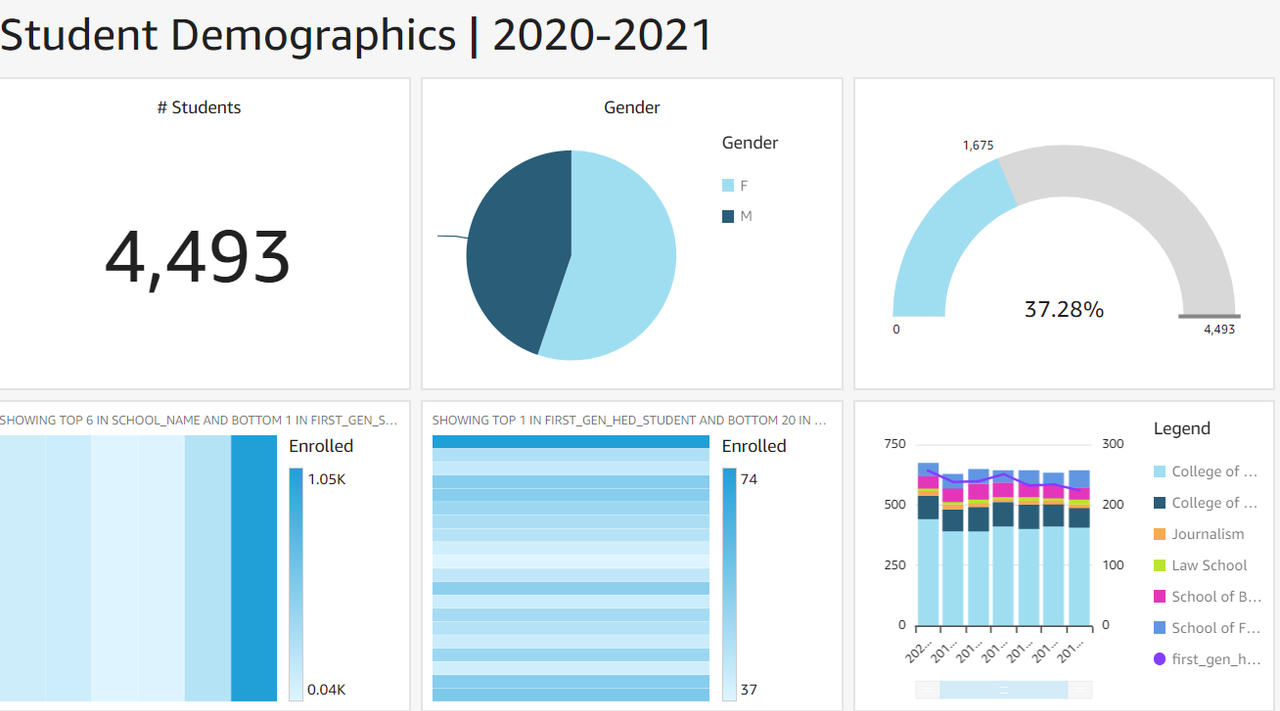
Lab#4 : Redshift
요약
완전 관리형 데이터 웨어하우스 서비스로, 복잡한 분석 쿼리를 지원하도록 설계 됨
관리 규모가 큰 데이터베이스를 운영할 경우, Redshift 사용하기를 권장
Redshift
- Redshift cluster architecture
- Leader node
- SQL 엔드포인트
- 메타데이터 저장
- ML 최적화
- Compute nodes
- 로컬, 컬럼형 스토리지
- 쿼리를 병렬로 실행
- Amazon Redshift Spectrum nodes
- 데이터 레이크에 대해 직접 쿼리 실행
- Leader node
- Data Modeling
- STAR 등 다양한 데이터 모델과 함께 사용 가능
- Data load & unload
- 일부 Redshift 데이터 로드 작업은 여러 트랜잭션을 사용하고, 다른 작업은 단일 트랜잭션을 사용함
- 매번 리더 노드를 통과하며, 별도 트랜잭션이 필요한 데이터 로딩 : INSERT, UPDATE, DELETE
- 리더 노드를 한 번만 참여시키고 컴퓨팅 노드를 병렬로 참여시키는 데이터 로딩 : COPY, UNLOAD, CREATE TABLE, INSERT INTO
- 데이터 Load 시
- 가능할 때마다 COPY 를 사용하여 데이터 로드
- 테이브 당 단일 COPY 명령 사용
- COPY 가 불가능할 경우 다중 행 insert 사용
- 스테이징 테이블을 사용하여 upsert
- Redshift Spectrum
- Amazon S3에 저장된 외부 데이터에 대한 SQL 쿼리를 허용
그 외 : row-oriented 와 column-oriented 형의 차이 row 형은 OLTP 일 때 무조건 사용해야 하지만, 그 외의 경우 column 으로 저장할 때 빠르게 index 참조를 할 수 있음
실습
- Redshift 를 생성
- S3에서 데이터를 읽어와서 테이블을 생성 (저장 공간이 다른 두 개의 table 을 Redshift 에서 Join 할 수 있음)
- LMS 시각화 등이 가능
감상
데이터 저장, 분석을 위한 다양한 서비스를 체험해 볼 수 있어서 유익했다.